Nos actualités
Take over Legacy : reprendre le contrôle!
")
J’ai toujours aimé travailler avec des applications legacy. D’une part, car cela signifie que c’est une application utilisée en production. On ne travaille peut-être pas avec la dernière technologie, le dernier framework à la mode mais on contribue à apporter de la valeur aux utilisatrices et utilisateurs et à améliorer leur expérience utilisateur. Et c’est là que je tire de la satisfaction dans mon travail. D’autre part car cela représente un challenge multi-facette. En plus des problématiques techniques, on se confronte la plupart du temps à des défis humains et organisationnels. C’est peut-être ici que l’IA génératrice de code trouve ses limites
Mais alors, comment détecte-t-on que l’on se trouve face à une application legacy ou du code legacy?
On peut bien sûr lister les symptômes techniques classiques comme :
- certains code smells très répandues: primitive obsession, large class, long parameter list, etc….
- une absence ou peu de tests automatisés
- des technologies dépassées, qui contiennent des CVE et ou qu’il est difficile de mettre à jour.
- et j’en oublie certainement beaucoup d’autres.
D’autres symptômes peuvent nous mettre la puce à l’oreille, comme par exemple :
- le peu de mise en production est vu comme risqué et un événement à part entière pour l’équipe
- lorsque le développement d’une fonctionnalité X entraîne des régressions sur une fonctionnalité Y qui de prime abord semble complètement décorrélée.
- lorsque les estimations des développeuses et développeurs semblent importantes même pour un petit changement.
- lorsque l’on demande à sa Product Owner à partir de quelle estimation elle accepte d’abandonner le développement d’une nouvelle fonctionnalité
Il s’agit bien sûr d’une liste non-exhaustive et chaque personne et ou équipe peuvent avoir une sensibilité différente de ce qu’est du code legacy. Les métriques DORA sont une très bonne piste pour démarrer.
Une fois ce constat posé, beaucoup imaginent qu’il faut réécrire from scratch l’application, repartir sur des bases saines pour se débarrasser du code legacy. Mais en réalité, qu’est-ce qu’il nous fait croire que les problèmes sont purement technologiques ? Écrire des codes smells, ne pas écrire de tests sont des pratiques qui sont totalement décorrélées des technologies utilisées. Et qu’est ce qui nous fait croire que cette fois-ci, le code écrit sera plus propre alors que les pratiques de l’équipe, qu’elles soient techniques ou organisationnelles, n'ont pas changé ?
Réécrire from scratch est, à mon sens, une fausse bonne idée. En réalité, l'équipe doit travailler à reprendre le contrôle de son projet. Cela passe par des compétences techniques, des compétences en software crafting et une véritable dynamique d’amélioration continue dans l’équipe.
Mon retour d’expérience
Cette petite introduction a permis de poser quelques bases pour vous présenter plus en détail mon retour d’expérience sur un projet sur lequel je travaille depuis plus d’un an maintenant et sur lequel nous nous efforçons de reprendre le contrôle.
Disclaimer!
Je ne souhaite en aucun cas blâmer ni montrer du doigt des personnes. Il s’agit uniquement de montrer des problèmes, des pratiques et des manières de faire afin de s’améliorer.

Des tests oui, mais sans assertion!
Lorsque l’on impose à une équipe technique d’avoir un taux de couverture élevé, quel est son premier réflexe ? Faire monter la couverture de code artificiellement avec des tests sans assertions bien sûr ! C’est évidemment une faute professionnelle et un cadeau empoisonné pour les personnes qui travaillent sur le projet. C’est aussi une idée terrible pour plusieurs raisons. Premièrement, la couverture de code vous donnera un faux indicateur de la qualité du code et naïvement on peut penser que l’on peut se lancer dans un refactoring du code car ce dernier est correctement couvert. Deuxièmement, le code de test reste du code et c’est donc du code à maintenir, à faire évoluer et qui d’autant plus consomme des ressources de compilation, du temps de build…
Le plus navrant ici est que l’outil d’analyse de la couverture de code que nous utilisons, n’est pas capable de trier les tests avec et sans assertion et donc ces tests rentrent dans le calcul de la couverture 😞.
Ici pour reprendre le contrôle, plusieurs solutions s’offrent à nous :
- Une solution radicale est de supprimer tous les tests sans assertions. Comme l’on a dit, ces tests sont juste du bruit consommateur de ressources. Les supprimer va permettre de retrouver un taux de couverture qui ne nous ment pas.
- Une solution moins brutale est de reprendre les tests sans assertions, comprendre leur logique, leur scénario pour ensuite ajouter les assertions adéquates. C’est une tâche assez chronophage car on essaie de comprendre une logique fonctionnelle pour l’écriture d’un test qui en réalité n’en n’a aucune.
Il ne faut pas s’arrêter là car même si les autres tests ont des assertions, rien ne garantit que les assertions soient correctes. Ici pour réaliser une évaluation de la qualité et de la pertinence des tests, on peut faire du mutation testing. Cela nous donnera une bonne idée de la qualité de notre base de test.
Enfin, on ne le répètera jamais assez, mais il est important de prendre autant soin si ce n’est plus de notre base de code de test que de notre base de code de production.
Un bug = un test !
Une pratique, qui à mon sens devrait être un automatisme pour les développeuses et les développeurs est que lorsqu’un bug est détecté, on écrit un test pour le reproduire, s’assurer qu’il ne se reproduira plus, pour ensuite le corriger.
Cela peut paraître “fou” mais j’ai dû avoir des échanges de plusieurs dizaines de minutes pour expliquer le bien-fondé de cette pratique là où on me rétorquait que ce n’était pas nécessaire d’écrire un test puisque le code était déjà couvert… (peut-être avec un test sans assertion). C’est ce genre de pratique qui permet, petit à petit, de reprendre le contrôle.
Migration technique
Reprendre le contrôle c’est également basculer sur des technologies modernes et populaires qui améliorent l’expérience développeur, permettent de trouver plus facilement des développeuses et développeurs, limitent le nombre de bug avec une meilleure compréhension du framework. Dans notre cas, le projet se basait sur le framework Apache TomEE. Un framework qui malheureusement présente certaines lacunes comme une documentation lapidaire, une gestion compliquée des propriétés externes, une expérience développeur calamiteuse, une certaine complexité pour l’écriture des tests et une intégration difficile avec d’autres composants de l'écosystème Java. Nous avons fait le choix alors de migrer notre projet vers le framework Spring Boot.
Afin de migrer tout en reprenant le contrôle, nous avons choisi de migrer endpoint par endpoint, de tirer les dépendances, de transformer les beans, etc…, en somme de remonter le fil d’ariane et bien sûr d’écrire les tests Spring associés pour s’assurer du bon fonctionnement de la nouvelle base de code. Réaliser cette migration de cette manière a permis de s'assurer à chaque endpoint migré que l’application continue de fonctionner et finalement de construire une base de test fonctionnelle solide.
Cette migration ne fût pas sans écueil et l’écriture de tests en parallèle nous a permis de garder la tête froide et d’avancer sereinement. Un écueil qui m’a particulièrement marqué fût durant la migration d’OpenJPA vers Hibernate. Hibernate a râlé car une classe annotée @Entity possède deux champs annotés avec le même @Column! Là où OpenJPA ne voyait pas le problème….
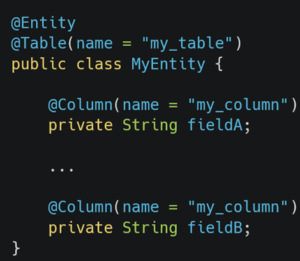
Dit d’une manière plus claire, nous avions en base de données, une colonne d’une table qui est utilisée par deux champs de l’entité Java. On se retrouve dans une situation ubuesque où l’on ne sait pas à quoi correspond la valeur en base !
Un regard neuf ?
Travailler sur une application legacy, c’est aussi s’approprier et comprendre l’existant afin d’en juger si certaines choses sont toujours nécessaires. J’en veux pour exemple un cas concret. La construction de l’image Docker se fait sur notre pipeline d’intégration continue où il fallait absolument donner la version d’une dépendance afin qu’elle soit ajoutée au livrable.
En creusant plus en détail sur ce qu’était cette dépendance et en quoi elle était nécessaire, je me suis rendu compte qu’il s’agissait d’un fichier vide ! En réalité, cette dépendance ne servait strictement à rien mais l’équipe restait persuadée qu’il fallait bien saisir une certaine version pour construire l’application.
Stabilité vs Vitesse ?
Lorsque l’on travaille sur une application legacy, on a tendance à tester, retester et tester encore la nouvelle version de l’application avant une mise en production. On craint des effets de bords, on présume de la fragilité de l’application et on cherche à se protéger au maximum. C’est une vision tout à fait légitime mais qui pour autant souffre de biais.
En réalité, le livre “Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations” définit quatre métriques:
- deux métriques de vitesse : lead time et deployment frequency.
- deux métriques de stabilité : MTTR et change failure rate.
Et le plus important est que ces métriques évoluent ensemble. On ne peut pas augmenter sa stabilité sans augmenter sa vitesse et inversement. C’est une idée reçue répandue qui consiste à croire qu’augmenter la fréquence des déploiements compromet la stabilité. Les recherches du livre réfutent ce mythe, montrant que l’automatisation, l’intégration et le déploiement continus (CI/CD) ainsi que les mises en production fréquentes améliorent en réalité à la fois la vélocité et la fiabilité.
Les pratiques
Reprendre le contrôle ne passe pas que par des sujets techniques, c’est aussi un ensemble de pratique et de volonté d’amélioration continue. Par exemple, nous avons mis en place en vrac :
- des sessions de pair programming,
- de la revue de code assidues,
- de l’encadrement pour maîtriser l’écriture de tests qui ajoutent de la valeur,
- des sessions sur comment s’attaquer à du code legacy difficilement testable avec des méthodes comme le golden master testing
- une session hebdomadaire commune pour discuter et résorber la dette technique
- une acculturation des bonnes pratiques lors de partage autour de talks et de conférences.
Par ailleurs, il est aussi important de concentrer ses efforts sur les personnes volontaires et désireuses de s’améliorer. Comme dit le dicton, on ne saurait faire boire un âne qui n’a pas soif.
L’impact de l’IA
J’aimerais terminer sur l’impact de l’IA génératrice de code. Elle nous a permis de comprendre, d’appréhender la complexité sur des méthodes de plus de 2000 lignes avec une charge cognitive énorme. Elle nous a permis également d'assainir et d’étayer notre base de test. Cependant, ces propos sont à nuancer car pour cela nous devons absolument accompagner l’IA sur les bonnes pratiques de code, travailler en baby step, contrôler le code généré, etc…. Il est très facile de demander à l’IA de vous générer une classe de tests sur du code legacy mais attention au résultat ! Notre IA s’inspirant fortement du code existant, il est essentiel de lui donner au préalable des exemples et des bonnes pratiques.
Utiliser l’IA pour travailler avec une base de code complexe, c’est comme travailler avec un enfant de 4 ans ! Il faut sans cesse lui rappeler le contexte, le but recherché, ne pas le laisser se disperser et contrôler à chaque étape les outputs.
Technologies associées