Nos actualités
DEVOXX 2025 : on vous dit tout !

Devoxx ! Avec plus de 4500 visiteurs par jour, plus de 300 orateurs et oratrices, 70 exposants, c’est LA conférence incontournable pour les développeurs de France !
Avec des conférences et des ateliers autour de l’écosystème Java, Spring, Python, Kubernetes, Apache Kafka, l’IA, les performances, le DevOps, la sécurité, la data et bien plus encore !
Nos collaborateurs Victor GALLET, Eric SANCHEZ, Sébastien SCHNEIDER, Pierre REVELLIN, Elodie WAN, Helena LI, Nicolas SILBERMAN, Philippe CHANG, Oguzhan KILIC, Guillaume GUERARD, Alexandre WINTREBERT, Hiba Nafissa MEZGHICHE, Zakaria BENJEBARA, Thibault MONEGIER DU SORBIER, Mohamed EL MRIHY et Jean Baptiste LATAPY ont pu découvrir de nouveaux concepts, de nouveaux outils et repartir avec de nouvelles idées pour Bpifrance, ils vous disent tout !

Retour sur les talks !
L’Intelligence Artificielle n’existe pas – Luc Julia
Luc Julia, cocréateur de Siri, commence par une déclaration audacieuse : l'intelligence artificielle n'existe pas. Il explique que le terme intelligence artificielle a été inventé en 1956 par des chercheurs, mais que les promesses faites à l'époque n'ont pas été tenues, menant à plusieurs "hivers de l'IA" où l'intérêt et le financement ont diminué.
Il est aussi venu nous rappeler durant cette première Keynote que les IA ne sont que des outils que l’utilisateur doit appréhender. Les IA ne contiennent pas de réelles intelligences : elles sont composées de statistiques, de probabilité, qui peuvent leur causer des « hallucinations ». Il faut donc les surveiller, ou les spécialiser, afin d’en faire une bonne utilisation.
Il distingue plusieurs types d'IA développés au fil des décennies :
- Les systèmes experts des années 1960, basés sur la logique et les arbres de décision.
- Le machine learning des années 1990, rendu possible par l'essor d'Internet et du big data.
- Le deep learning, une évolution du machine learning avec plus de données et de puissance de calcul.
Luc Julia se concentre ensuite sur les IA génératives, qui ont gagné en popularité depuis 2018. Il critique l'idée que ces IA représentent une révolution, préférant les voir comme une évolution des techniques statistiques précédentes. Il souligne que ces IA utilisent des quantités massives de données pour générer des résultats, mais qu'elles ne sont pas créatives.
Il déconstruit plusieurs mythes autour de l'IA :
- L'IA de Hollywood : les scénarios de science-fiction comme Terminator ou Her sont irréalistes.
- L'IA générale (AGI) : l'idée d'une IA capable de tout faire mieux que les humains est une illusion.
- L'IA créative : les IA génératives ne créent rien par elles-mêmes ; elles génèrent des résultats basés sur les instructions humaines.
La comparaison est saisissante : les IA sont des outils comme des marteaux ou des tournevis. Ces outils sont spécialisés et peuvent être utilisés à bon ou mauvais escient, ce sont les humains qui décident de leur utilisation !
Les IA ne remplaceront pas les humains, mais elles peuvent aider à être plus efficaces. Les développeurs doivent considérer les IA comme des outils puissants pour améliorer leur travail, tout en restant conscients de leurs limites.
Luc Julia nous offre une perspective rafraîchissante et réaliste sur l'IA, démystifiant les idées fausses et soulignant l'importance de l'humain dans l'utilisation de ces technologies. Une conférence riche en enseignements et en réflexions pour tous ceux qui s'intéressent à l'avenir de l'IA.

KEYNOTE : Elodie Mielczareck - Langage, IA et propagande : la guerre des récits a déjà commencé
Elodie Mielczareck, experte en sémiologie, a captivé son audience lors de sa conférence intitulée "Langage, IA et propagande : la guerre des récits a déjà commencé". Elle nous partage d’abord le rapport complexe avec le langage, avant de nous proposer une plongée au coeur de son intervention : la manipulation des récits à travers le langage et la technologie.
La Publicité et la Manipulation des Signes
Elle utilise l'exemple d'une publicité d'Apple de 1984 pour illustrer comment les signes sont utilisés pour évoquer des imaginaires historiques et mythologiques, ces récits sont souvent détournés à des fins mercantiles, créant ainsi une nouvelle chaîne de langage.
La Sémiologie et Umberto Eco
Elodie rend hommage à Umberto Eco, célèbre sémiologue, et explique que la sémiologie permet de décrypter les signes au-delà de la simple dimension morale, les sémiologues cherchent à comprendre les processus de création de sens.
L'Umwelt et le Langage
Le concept d'Umwelt est un terme désignant l'environnement sensoriel d'un individu, partant de ce postulat, le langage est un Umwelt pour les humains. D’ailleurs la technologie modifie également notre rapport au réel, devenant un nouvel Unwelt.
La Post-Vérité et les Fake News
Pendant la conférence, la notion de post-vérité est aussi abordée. Popularisée en 2016, on trouve bon nombre d’exemples de fake news des deux côtés de l'Atlantique, notamment l'élection de Donald Trump et le Brexit, la désinformation n'est pas l'apanage d'un seul camp politique.
Les Niveaux de Simulation du Réel
Voyage à travers différents niveaux de simulation du réel :
- Niveau -1 : Le signe est lié au réel, dans un univers hérité des Lumières.
- Niveau -2 : Le signe commence à se détacher du réel, dans le champ de l'information.
- Niveau -3 : Le signe fonctionne en auto-référentialité, dans l'infofiction.
- Niveau -4 : Le signe devient un simulacre pur, le réel disparaît.
Elodie cite Jean Baudrillard, sociologue français, qui a théorisé ces niveaux de simulation et l’importance de ne pas confondre simulation et illusion.
En rappelant que dans la guerre des récits, ce qui compte, c'est qui détient le pouvoir de créer ces récits, l’audience est encouragée à réfléchir à leur rôle dans cette dynamique.
Elodie Mielczareck nous invite à prendre conscience de l'impact du langage et de la technologie sur notre perception du réel, et à rester vigilants face aux manipulations narratives.
KEYNOTE : Ophélie Coelho - La territorialisation des infrastructures comme levier de pouvoir
Ophélie Coelho, spécialiste en géopolitique numérique, a offert une conférence fascinante intitulée "La territorialisation des infrastructures comme levier de pouvoir".
Elle commence par expliquer la notion de territorialisation des infrastructures, en utilisant une carte historique du réseau télégraphique de 1903 pour illustrer la concentration de pouvoir à travers les infrastructures de communication.
Tout commence par la bataille navale de Tsushima en 1905 pour montrer comment les réseaux télégraphiques étaient utilisés à des fins géopolitiques, le parallèle avec des événements contemporains, comme le blocage par les États-Unis du câble Pacific Light Cable Network en 2019 pour des raisons de sécurité.
La décentralisation et l'interdépendance des composants logiciels et matériels est complexe. On remarque notamment en Afrique australe la concentration des câbles sous-marins et des centres de données dans certaines régions, comme l'Afrique du Sud, et les dépendances créées par cette répartition inégale. Les principaux acteurs du secteur des centres de données en Afrique, comme Terraco et DigitalUlti, transforment le territoire en créant des infrastructures géantes.
La Théorie Centre-Périphérie
On assiste à la mise en place de la théorie de l'indépendance, une approche néo-marxiste, pour expliquer la concentration du pouvoir autour des points de passage obligés dans les réseaux numériques.
Les Empires Privés et la Big Tech
Les empires privés, comme Google et Amazon, et les empires étatiques, possèdent un pouvoir considérable et une capacité à influencer les marchés et les sociétés.
Conclusion et appel à action
En conclusion, il est nécessaire d’agir contre la concentration de pouvoir des géants du numérique, en proposant des approches défensives et offensives pour protéger la société et développer des technologies indépendantes.
KEYNOTE : Rachel Dubois - Dans les coulisses des géants de la Tech !
Rachel Dubois, experte en product management et coaching agile, a offert une conférence captivante intitulée "Dans les coulisses des géants de la Tech !". Tout d’abord, il s’agit de déconstruire les mythes autour de l'innovation et de l'agilité dans les grandes entreprises technologiques et d’insister sur le fait que l'innovation n'est pas réservée à une élite créative, mais repose sur des pratiques concrètes et mesurables.
Dans notre métier, nous avons tendance à se méprendre sur la définition du mot vitesse. Pour beaucoup d’entre nous, lorsqu’on parle de vitesse, on pense à des choses comme lead time ou continous deployment. On pense à notre capacité technique à livrer rapidement. Mais en réalité, lorsqu’on se positionne d’un point de vue produit, la vitesse est la capacité de livrer rapidement de l’impact aux utilisateurs, des changements.
Par cette introduction, nous retrouvons l’essence de ce talk : remettre l’utilisateur au centre de nos problématiques afin de se démarquer des concurrents et de gagner des parts de marchés. Et c’est ce que les géants de la tech ont compris.
L'Illusion de l'Agilité
Critique de l'illusion et de l'agilité, où la vitesse et la vélocité sont souvent confondues avec l'innovation réelle, l’experte invitée a insisté sur l'importance de mesurer l'impact des produits sur les utilisateurs et le marché.
Exemple de Spotify
Pour mieux illustrer le processus de gestion de produits ses propos, elle a pris l'exemple d'Anna, une product manager fictive chez Spotify. « Anna commence sa journée en vérifiant les données de performance et en identifiant les problèmes. Son équipe, composée de designers, data scientists et ingénieurs, collabore pour comprendre les problèmes des utilisateurs et tester des solutions », explique l’experte.
Le Framework D.I.B.B et Importance des Tests et de l'Expérimentation
En présentant le framework D.I.B.B utilisé chez Spotify, elle a notamment souligné que les entreprises comme Spotify réalisent des milliers de tests A / B en parallèle pour optimiser leurs fonctionnalités en insistant sur l'importance de tester rapidement et de manière itérative pour maximiser l'apprentissage.
- Data - Collecte des données
- Insights - Compréhension des données.
- Beliefs - Formulation d'hypothèses.
- Bet to pursue - Tests des hypothèses.
Systèmes Nerveux, Immunitaire et Circulatoire , quel est le rapport ?!!
La conférence a également mis en évidence les similitudes entre les entreprises technologiques et les organismes vivants disposant de trois systèmes vitaux :
- Système nerveux : Capacité à détecter et comprendre les changements externes : ce sont les capteurs, les métriques que l’on peut mettre en place pour capter, sentir nos utilisateurs
- Système immunitaire : Détection et élimination des anomalies : c’est l’excellence technique. On ne peut pas prétendre à livrer de la valeur rapidement sans un code de qualité, des tests, de l’observabilité, etc….
- Système circulatoire : Circulation fluide de l'information et des données. C’est le flow d’informations qui circule dans l’entreprise pour alimenter nos choix. Savoir exactement comment notre application est utilisée, connaitre l’impact commercial et financier que peut avoir le déploiement d’une nouvelle fonctionnalité.
La Culture de l'Innovation
Cela a permis à Rachel Dubois de souligner que la culture d'innovation ne dépend pas d'un leadership visionnaire, mais de la compréhension que la technologie est au cœur du business. Elle encourage les entreprises à intégrer les ingénieurs dès le début du processus de conception et à favoriser une collaboration étroite entre les équipes.
La conférence s’est conclue par un appel à la réévaluation des pratiques de product management en adoptant une nouvelle méthodologie qui consisterait à se concentrer sur l'expérimentation plutôt que sur la simple livraison de fonctionnalités, et de valoriser l'apprentissage continu.
En bref, une présentation géniale avec quelques tacles aux fausses pratiques Agile.
Cette conférence inspirante et riche en enseignements dédié à la tech invite à repenser notre approche de l'innovation et de l'agilité, en mettant l'accent sur l'impact réel et mesurable des produits.

John Doe et Jhon Doe sont dans un bateau : la magie derrière l'Entity Resolution - Arnaud Esteve
Après c’être vu refusé l’entrée de l’amphithéâtre car déjà plein, nous sommes allés voir cette présentation un peu par hasard et c’est totalement sans regret !
Arnaud nous a présenté ce qu’est l’Entity Resolution, qui vise à fusionner et à dédoublonner des données de différentes sources.
Prenons l’exemple d’une base de données de clients que l’on souhaite fusionner avec notre base de données. On peut imaginer définir des règles simples qui vont nous permettre de regrouper les données clients. Par exemple, regrouper nos clients s’ils ont le même mail, puis le même nom, puis le même prénom, la même adresse, etc…. Mais en réalité, on se rend compte que l’on va très vite se heurter à une explosion combinatoire avec l’accumulation de ces heuristiques et que cela reste assez fragile. En effet, se dire que l’on va identifier des clients en se basant sur le même nom, ne prends pas en compte les différentes orthographes pour un même nom. Arnaud, le speaker, prend justement comme exemple son prénom qui peut s’écrire Arnaud, Arnaut, Arnault, Arnau, etc….
C’est ainsi que pour réaliser la fusion de nos bases de données, on va plutôt utiliser une approche, des techniques du monde de la data science.
L’Entity Resolution ou Entity Matching se décompose en 5 étapes : cleansing, linking, clustering, canonicalisation et check.
Cleansing, autrement dit la préparation des données.
Cette étape consiste à “nettoyer” notre donnée mais également à réfléchir à sa représentation pour les prochaines étapes. S’il on reprend l’exemple des noms et prénoms ou l’orthographe peut varier, on peut alors opter pour une représentation phonétique. Un autre exemple est celui des adresses, deux adresses complètement différentes peuvent en réaliser situer un même lieu. On peut alors opter pour une représentation sous forme de géo-hashing.

Linking
Durant cette phase, on cherche à regrouper nos données, à faire du partitioning. On va réaliser des calculs de distance entre nos données pour établir des liens. Des aspects du domaine métier peuvent également être pris en compte pour affiner les liens.
C’est durant cette étape que le speaker introduit la bibliothèque SPLINK : bibliothèque spécialisée dans l’Entity Resolution et développée par le ministère de la justice du Royaume-Uni.
Clustering
Une fois les liens établis, on peut alors créer des groupes suivant les calculs de distance que l’on a établi précédemment.

Canonicalisation
Ici il s’agit de fusionner, de merger nos données au sein des groupes. En prenant par exemple deux clients que l’on a identifiés comme étant un seul client, quelle valeur a gardé pour le mail, le nom, le prénom, etc…. On peut alors utiliser nos connaissances métier, avoir des heuristiques et calculer des mesures de similarité au sein des groupes.
Check
C’est l’étape de validation. Comment s’assurer que les groupes produits sont bons ? Pour cela deux approches : on peut évaluer notre modèle sur un échantillon et en déterminer sa qualité, on peut également faire de l’évaluation continue ou l’on va s’intéresser aux groupes, leur taille, leur “diversité” avec une mesure de leur entropie.
En conclusion, une conférence vraiment intéressante et qui a permis de garder en tête le fait que pour résoudre un problème, il est important de s’intéresser à d’autres domaines, comme la data science.
*QUICK TAKE AWAY*
L’Observabilité pour les devs: outils-clé pour survivre quand la prod plantera – Alexandre Moray, Florian Meuleman
Encore une excellente conférence par Takima, axée sur des outils d’observabilité opensource : OpenTelemetry, et SigNoz. Parmi les projets open source, OpenTelemetry se classe deuxième en termes de nombres de contributeurs dans les sujets Devops, juste après Kubernetes. Il est possible donc de mettre en place l’intégralité des fonctions d’observabilité avec OpenTelemetry : métriques, logs, et traces, puis les transverser dans SigNoz.
A retenir : utiliser les agents plutôt que des JDK afin de minimaliser les impacts sur le code, et se servir d’un Gateway pour rassembler pour les signaux afin d’avoir une configuration globale. Cela permet donc de modifier l’APM sans soucis.
Comment allonger notre build nous a fait gagner du temps ? - Vincent Galloy et Eric Le Merdy
Durant cette session, les speakers ont présenté un certain nombre de steps de leur pipeline qui leur ont permis de gagner du temps tout au long du process de développement.
Il s’agit de beaucoup de choses assez communes (du moins nous l'espérons ;)) comme :
- renovate ou dependabot pour la gestion des montées de version des dépendances,
- Formatage du code avec spotless
- Style du code avec PMD
- Respect des règles d’architecture avec PMD également. Ils ont dans un premier temps mis en place ArchUnit mais ont préféré PMD.
- Migration de la base de données avec Flyway
- Gestion de la rétrocompatibilité des API avec une validation faite sur les spécifications d’OpenAPI. Il s’agit d’un plugin custom.
- Analyse des dépendances inutiles avec Maven Dependency Analyzer. Attention avec cette analyse car certaines librairies sont utilisées uniquement au runtime !
Les speakers ont conclu sur le fait qu’ils sont très satisfaits du cadre qu’ils ont mis en place. Ce cadre est en évolution constante et de nouvelles règles PMD sont ajoutées.
Full stack Java, du dev à la prod en passant par l'infra – Stéphane Philippart
Un deep dive sous forme de programmation en live, avec une stack complète java, du back à l’infra. Le sujet : créer un chatbot faisant appel à une IA générative pré-entraînée, grâce à OVHCloud.
A retenir : Jbang, qui permet de faire des scripts en java sans la verbosité de celle-ci, et les projets d’infrastructure à surveiller chez OVH, comme Mistral AI qui a décidé de migrer chez cette dernière !
Vos requêtes SQL jusqu’à 10000 fois plus rapides, durablement - Alain Lesage
Pourquoi PostgreSQL ? PostgreSQL est une base de données relationnelle issue d’un projet universitaire. C’est un projet libre et communautaire. C’est aussi un projet modulaire et extensible.
Durant ce talk, nous avons appris à choisir le bon type d’index suivant la donnée et les requêtes qui vont être exécutées.

Par exemple, il est important de créer un index fonctionnel. C’est-à-dire que si l’on sait que l’on va effectuer des transformations dans nos requêtes, par exemple upper ou lower, on peut créer un index avec cette transformation.
Durant cette présentation, on apprend également que PostgreSQL arrête de calculer les différents plans d’exécution d’une requête après plus de huit jointures. Or il se peut que certains ORM génèrent des requêtes avec un très grand nombre de jointures. Pour palier à ça, arrêter d’utiliser les ORM ou bien changer les paramètres système de la base join_collapse_limit et from_collapse_limit.

Enfin, si vous cherchez à savoir comment rendre une requête SQL 10 000 fois plus rapide, allez voir le blog post Une requête 10 000 fois plus rapide, sans ajouter d'index qui a inspiré le talk.
TDD et IA – Benoit Prioux
Un lunch talk court mais synthétique sur le sujet du TDD, encouragé chez Alan. Les IA ont une tendance à parfois halluciner des éléments de code, dû au manque de contexte. Il faut alors appliquer réellement le principe du TDD : écrire d’abord les cas de tests, y réfléchir, puis les faire générer par l’IA. Les tests doivent être d’abord rouge, puis on code ensuite les méthodes, afin de les faire passer au vert !
Attention ! Générer les tests à partir du code est une mauvaise pratique.
Optimisez vos applications Spring Boot avec CDS et Project Leyden – Sébastien Deleuze
Sébastien, Core Committer sur le projet Spring Framework nous a présenté trois façons d’améliorer le temps de démarrage de nos applications : CDS, AOT Cache, AOT Cache with profiling.

En bref, ces trois technologies reposent sur l’idée d’effectuer un training run de l’application afin de charger les classes de l’application puis de les rendre instantanément disponible lors du second démarrage. Ce qu’il faut savoir c’est que CDS existe depuis Java 9 mais est en réalité assez contraignant à l’usage. AOT Cache, décrit par la JEP-483, est son digne successeur et sera disponible pour Java 24. On peut s’attendre à des améliorations d’ici là.
On peut également s’attendre à un support Spring Boot pour faciliter l’usage de AOT Cache comme ce qui est déjà fait avec CDS.
Enfin, Sébastien a terminé par présenter un tableau récapitulatif des différentes options d’optimisation d’une application Java : faire du natif avec GraalVM, utiliser CRaC ou AOT Cache.

45 min pour mettre son application à genoux : le guide complet du test de charge – Loïc Ortola

Une conférence dynamique de Takima sur les tests de charge avec l’outil Gatling permettant, à l’aide de scripts en plusieurs langages, de faire des tests de charge notamment avec des fausses requêtes utilisateurs. Une page HTML est ensuite générée avec les résultats, et la capacité moyenne d’utilisateurs concurrents possible sur un site web par exemple.
A retenir : Il faut s’y prendre tôt car les tests de charge révèlent bien des surprises, même avec une architecture que l’on pense peaufinée. Les résultats de Taki Ciné, l’application utilisée pour la démonstration ne pouvait supporter que 11 utilisateurs concurrents.
"Ça marche dans mon .devcontainer!" – Benoit Moussaud
L’onboarding des développeurs prend du temps, notamment à cause de l’installation et la configuration de l’environnement de développement. La solution : devcontainers, qui permet de définir l’environnement par du code, avec une intégration à VScode.
A retenir : grâce à un fichier json, on peut configurer tout l’environnement de dev grâce à des containers.
"Continuations: The magic behind virtual threads in Java" par Balkrishna Rawool, ING Bank
Il a présenté une des nouveautés de Java 21 : les threads virtuels. Les threads traditionnels sont coûteux en termes de ressources OS, chacun nécessitant sa propre pile mémoire alors que les threads virtuels sont plus légers, permettant d'en créer un grand nombre (des milliers voire des millions) sans surcharger le système.
"IA Générative, TDD et Architecture Hexagonale : Une Synergie Révolutionnaire ?" présenté par Clément Virieux, Ippon
Points clés :
- Le TDD guide la génération de code en définissant des cas passant, non passant et surtout les cas limites.
- Cette approche produit un code métier de meilleure qualité avec moins de bugs.
- L'Architecture Hexagonale structure efficacement le code généré.
- La combinaison de ces techniques améliore la fiabilité du code généré.
REX : Évoluer pour le plus grand événement sportif: Rust et gRPC de zero à la Prod presenté par Etienne Puissant et Bastien Sautéjeau, Betclic
Un rex intéressant sur l'utilisation de Rust et la mise en place du short polling sur les streams gRPC, permettant aux clients connectés de recevoir des updates en temps réel et à faible latence pour divers services.
Les avantages de Rust et gRPC incluent une performance impressionnante et une sécurité renforcées grâce à la gestion stricte de la mémoire et aux capacités de streaming bidirectionnel. Ils ont développé leur application avec une architecture événementielle utilisant NATS, un système de messagerie léger, et l'application est hébergé sur AWS. Le temps de mise en place de cette solution est de 2 mois !!!
Elasticsearch Query Language: ES/QL – David PILATO
La version 8.X.X d’Elasticsearch vient avec son lot de changement. Finis les requêtes elasticsearch complexe qui nécessite des requêtes toujours plus longues les unes que les autres, finis les dashboard Kibana qui nécessite des heures de mis en place. Avec le nouveau langage mis en place par Elasticsearch tout devient plus facile. Via un nouvel endpoint _query l’écriture de la requête est totalement modifié. Le langage se rapproche du sql afin de faciliter son utilisation :
C’est bien beau tout ça mais qu'est-ce que ça apporte de plus ? Et bien pas mal de choses :
- La donnée peut maintenant être au format csv, arrow pour être utilisable par des modèles d’IA,
- La création de colonnes dynamique depuis la requête directement,
- Enfin, une fonctionnalité demandée depuis des âges, la jointure entre index
Le moteur qu’est Elasticsearch apporte son lot de nouveautés mais il n’est pas le seul puisque Kibana vient compléter ces dernières. Nous pouvons maintenant créer nos dashboards depuis ces requêtes ES/QL et Kibana vient auto-compléter les requêtes en comprenant ce que nous souhaitons faire. Selon la donnée que nous affichons Kibana propose la vue la plus adapté et nous affiche un panel contenant toute la donnée de manière épurée.
Enfin, pour les techs pas de panique tous ces changements sont disponibles dans les clients mis à disposition pour utiliser elasticsearch au sein de vos applications donc à vos claviers !!!
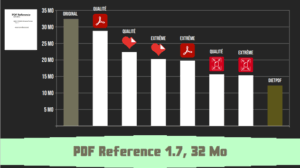
Plongée au coeur des PDF – Frédéric BISSON
Dans des organisations tels que les banques où les documents électroniques de type PDF affluent et prennent de la place, un enjeu de taille se pose, “le stockage des fichiers”. Bien que le stockage en lui-même n’est pas réellement un problème notamment via les différentes solutions aujourd’hui (AWS S3, ...) mais plutôt la taille des fichiers. Dans le but d’économiser de l’argent il est nécessaire d’optimiser ce stockage en réduisant la taille des fichiers sans perte. Pour ce faire différentes solutions au sein des PDF :
- Optimisation des chaînes de caractères (encodage des chaînes de caractères),
- Supprimer le superflu (oui il y a des choses qui ne servent à rien)

- Optimiser le code graphique
- Améliorer l’efficacité des filtres
- Cumuler les filtres
Enfin, le speaker nous présente son side project en Haskel DietPDF. Ce dernier propose des optimisations extrêmes sans perte meilleure que des projets du marché tels que ilovepdf ou même adobe.
Et si on faisait du simulation-driven development ? - Pierre Zemb (Clever Cloud)
Pierre dit “le chat noir” a rencontré de nombreux plantages notamment lorsqu’il était d’astreinte. Il lui est naturellement venu la volonté de vouloir s’en prémunir. Il a constaté plusieurs choses les environnements ne sont jamais isométriques (dev != prod) et surtout que le code est rarement assez robuste pour faire face à la complexité du monde réel. Une erreur imprévisible est vouée à se produire.
Vouloir tout tester ; vouloir tester tout ce qui devrait fonctionner ; c’est bien ; c’est honorable ; mais ça n’atteste du fonctionnement que des cas d’usages “normaux”, les golden paths et ça peut rapidement devenir très exhaustif. Le test E2E n’est pas parfait et ne prend pas en compte la complexité du monde ; il faut être en mesure de tester le pire.
Pierre nous propose en solution Le Deterministic Simulation Testing (DST) ou la science de tester l’occurence qui ne devrait jamais se produire. Ce concept implique d’insérer du chaos dans nos tests ; d’y introduire de la latence, des timeouts, des problèmes de disques, de la charge, etc. Bref, de la complexité du monde réel.
Son blog qui en parle en détail : https://pierrezemb.fr/posts/simulation-driven-development/
Kubernetes : 5 façons créatives de flinguer sa prod – Denis Germain (Lucca)
Super retour de terrain par Denis Germain enrichi par plusieurs années de création et de maintenance de clusters Kubernetes! Du concret, des frayeurs et surtout des conseils à suivre pour éviter les mauvaises aventures !
Denis nous offre 5 scénarios vécus et survécus ; 5 horror-stories de mainteneurs de clusters Kubernetes. Il y suit un schéma narratif strict où l’on décortique la situation initiale ; le problème en lui-même ; comment il l’a résolu et surtout ce que l’on devrait en retenir.
- Denis offre 5 take-aways précieux pour ceux qui souhaitent maintenir un cluster Kubernetes:
- Superviser son cluster n’est pas une option ;
- Favoriser le GitOps aux actions manuelles pour éviter les erreurs humaines ;
- Kubernetes c’est bien ; Kubernetes avec un garde-fou, c’est mieux ;
- L’élitisme de la mise en place d’un cluster “The Hard Way” n’est pas une bonne pratique ; Favoriser la pratique du Pet vs Cattle pour les noeuds Kubernetes.

BACK TO KEYNOTE
Stephan Janssen - Building full-stack AI agents From project generation to code execution
Stephan Janssen, cofondateur de Devoxx, a présenté une conférence fascinante intitulée "Building full-stack AI agents: From project generation to code execution".
Son enthousiasme pour les systèmes agentiques et l'impact révolutionnaire de l'IA sur la programmation est communicatif ! Il souligne qu'il ne code plus de manière traditionnelle, mais utilise des prompts pour générer du code, ce qui a considérablement augmenté sa productivité.
Démonstration Pratique grâce à l’utilisation de Claude, un outil d'Antropic, pour générer et corriger du code automatiquement permet la délégation des tâches complexes à l'IA, ce qui permet de se concentrer sur des aspects plus créatifs du travail.
La Construction d'Agents IA complets, en utilisant des outils comme LangChain4j et Spring AI permettent de créer des assistants de codage en quelques heures seulement.
L’utilisation d’outils comme fgrep et ripgrep sont utilisés pour introspecter les systèmes de fichiers et automatiser la gestion des projets.Ces outils ont une importance majeure dans l'ouverture de nouvelles possibilités pour les développeurs.
Le Model Context Protocol (MCP), une norme émergente soutenue par Antropic, OpenAI et Google, permet de fournir des outils via des fournisseurs de services, facilitant ainsi l'intégration et l'orchestration des agents. Il est possible de developper un plugin, ici : IntelliJ, DevOx GD, qui permet de basculer entre différents modèles d'IA et de supporter MCP. Ce plugin, développé en Java, est déjà utilisé par des milliers de développeurs.
Cependant, il ne faut pas minimiser les risques de sécurité liés à l'utilisation des agents IA, notamment la possibilité d'exécuter du code malveillant, des mécanismes de vérification sont nécessaires pour éviter les erreurs dangereuses.
En conclusion, Stephan insiste sur le fait que l'IA ne remplacera pas les développeurs, mais augmentera leur productivité, il les encourage d’ailleurs à adopter les outils d'IA pour rester compétitifs et innovants.
Il nous offre une vision inspirante de l'avenir de la programmation, où les agents IA jouent un rôle central dans la création et la gestion des projets. Une conférence riche en enseignements et en perspectives pour tous les passionnés de technologie.

Pawel Zajączkowsk - "Fighters, Bards, Druids and Wizards in It – how to talk to them "
Paweł Zajączkowski, expert en gestion d'équipes de développeurs, a offert un talk captivant "Fighters, Bards, Druids and Wizards in IT – how to talk to them".
Dans ce talk, c’est à travers les métaphores et les jeux de rôle que les différents types de personnalités dans le domaine de l’informatique vont être décrits.
Quatre archetypes emergent: les Combattants, les Bardes, les Druides et les Sorciers.
Les Combattants (Fighters)
Les combattants sont des personnes extroverties et orientées vers les tâches. Ils sont efficaces, décisifs et ambitieux. Cependant, ils peuvent être têtus et parfois trop directs. Dans le monde de la technologie, ils sont excellents pour résoudre des crises et accomplir des tâches rapidement, mais leur approche peut parfois manquer de finesse.
Les Bardes (Bards)
Les bardes sont également extrovertis, mais orientés vers les personnes. Ils apportent de l'optimisme, de la créativité et sont d'excellents communicateurs. Cependant, ils peuvent être égocentriques et indisciplinés. Dans l'informatique, ils sont parfaits pour les présentations et les interactions sociales, mais peuvent parfois négliger les détails techniques.
Les Druides (Druids)
Les druides sont introvertis et orientés vers les personnes. Ils sont fiables, observateurs et excellents pour résoudre les conflits. Cependant, ils peuvent être résistants au changement et indécis. Dans le domaine technologique, ils sont le soutien de l'équipe, mais peuvent parfois avoir du mal à prendre des décisions rapides.
Les Sorciers (Wizards)
Les sorciers sont introvertis et orientés vers les tâches. Ils sont analytiques, méthodiques et très intelligents. Cependant, ils peuvent être rigides et perfectionnistes. En informatique, ils sont excellents pour la recherche et les tests, mais leur quête de perfection peut ralentir les projets.
Comment Interagir avec Chaque Type
Combattants : Soyez direct, préparez des agendas clairs et soyez prêt à prendre des décisions rapides.
Bardes : Engagez-vous dans des discussions informelles, soyez énergique et valorisez leurs idées créatives.
Druides : Soyez sincère, évitez les surprises et offrez un soutien constant.
Sorcier : Fournissez des données et des faits, soyez précis et préparez-vous à répondre à de nombreuses questions.
La diversité des personnalités dans une équipe est d’une importance primordiale, les équipes composées de différents types de personnalités sont plus fortes et plus résilientes. Les leaders devraient reconnaître et valoriser les contributions uniques de chaque type de personnalité.

Paweł Zajączkowski nous offre une perspective ludique et éclairante sur la gestion des équipes en informatique, en utilisant des métaphores de jeux de rôle pour illustrer les dynamiques de personnalité. Un talk riche en enseignements et en conseils pratiques pour améliorer la communication et la collaboration au sein des équipes.
Voilà en quelques lignes, la substantifique moëlle que nous avons recueillie au cours de ces 3 jours !
Et enfin, une dernière chose à retenir 😉 :

Technologies associées